









Hi, I'm Zhiping (Arya) Zhang
/ʒiː pɪŋ ʒɑŋ/
👂
I'm a researcher,
🎈
I'm a second-year PhD student at Northeastern University in the Khoury College of Computer Sciences, supervised by Prof. Tianshi Li, and also a member of PEACH (Privacy-Enabling AI and Computer-Human interaction) Lab.
My research focuses on developing trustworthy agentic AI systems that support human-AI collaboration for preserving human privacy. I'm particularly interested in:
1) understanding privacy challenges in (personalized) agentic AI systems [1, 2, 3, 4, 5];
2) leveraging model capabilities and complementing human effort (e.g., supporting human autonomy) to align AI behavior with individuals’ privacy preferences in real-world applications [6, 7].
I'm actively looking for Research Internship opportunities for 2026!
In 2019 Dutch Design Week, Eindhoven, credit by Jianli Zhai
In 2024 iF Award Ceremony, Berlin,
credit by Kaixi Zhou
In 2019 Social Robotics Lab, Eindhoven, credit by SociBot
Before my PhD study, I built real-world Human-AI interaction systems in industry, working as a UX researcher and designer (B2B) at ALIBABA, and later as an AI product manager (2C) at a unicorn company FITURE. My landed projects on the market brought tangible benefits to users, achieved commercial success, and have been recognized with top international events:
🏆 IF Design Award, Red Dot Award, IF Talent Award, Dutch Design Week
I do research.
I conduct mixed-methods research to understand how LLM systems shape human privacy decisions and trust. I build protpo and run experiments to measure, and address these challenges.
My work has identified both model-side and human-side vulnerabilities, including users’ flawed mental models and overtrust in LLM-based systems as key risks, as well as different human behavioral and perceptual patterns that hinder effective human oversight.


. Large Language Model (LLM) agents require personal information for personalization in order to better act on users' behalf in daily tasks, but this raises privacy concerns and a personalization-privacy dilemma. Agent's autonomy introduces both risks and opportunities, yet its effects remain unclear. To better understand this, we conducted a 3 x 3 between-subjects experiment (N=450) to study how agent's autonomy level and personalization influence users' privacy concerns, trust and willingness to use, as well as the underlying psychological processes. We find that personalization without considering users' privacy preferences increases privacy concerns and decreases trust and willingness to use. Autonomy moderates these effects: Intermediate autonomy flattens the impact of personalization compared to No- and Full autonomy conditions. Our results suggest that rather than aiming for perfect model alignment in output generation, balancing autonomy of agent's action and user control offers a promising path to mitigate the personalization-privacy dilemma.
A Study on Personalization-Privacy Dilemma in LLM Agents
Zhiping Zhang, Yi Evie Zhang, Freda Shi, Tianshi Li
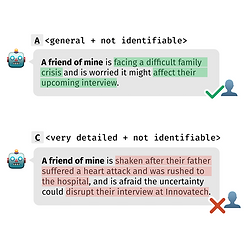
. Aligning AI systems with human privacy preferences requires understanding individuals' nuanced disclosure behaviors beyond general norms. Yet eliciting such boundaries remains challenging due to the context-dependent nature of privacy decisions and the complex trade-offs involved. We present an AI-powered elicitation approach that probes individuals' privacy boundaries through a discriminative task. We conducted a between-subjects study that systematically varied communication roles and delegation conditions, resulting in 1,681 boundary specifications from 169 participants for 61 scenarios. We examined how these contextual factors and individual differences influence the boundary specification. Quantitative results show that communication roles influence individuals' acceptance of detailed and identifiable disclosure, AI delegation and individuals' need for privacy heighten sensitivity to disclosed identifiers, and AI delegation results in less consensus across individuals. Our findings highlight the importance of situating privacy preference elicitation within real-world data flows. We advocate using nuanced privacy boundaries as an alignment goal for future AI systems.
Bingcan Guo, Eryue Xu, Zhiping Zhang, Tianshi Li


. Language model (LM) agents that act on users' behalf for personal tasks (e.g., replying emails) can boost productivity, but are also susceptible to unintended privacy leakage risks. We present the first study on people's capacity to oversee the privacy implications of the LM agents. By conducting a task-based survey (N=300), we investigate how people react to and assess the response generated by LM agents for asynchronous interpersonal communication tasks, compared with a response they wrote. We found that people may favor the agent response with more privacy leakage over the response they drafted or consider both good, leading to an increased harmful disclosure from 15.7% to 55.0%. We further identified six privacy profiles to characterize distinct patterns of concerns, trust, and privacy preferences in LM agents. Our findings shed light on designing agentic systems that enable privacy-preserving interactions and achieve bidirectional alignment on privacy preferences to help users calibrate trust.
Privacy Leakage Overshadowed by Views of AI:
A Study on Human Oversight of Privacy in Language Model Agent
Zhiping Zhang, Bingcan Guo, and Tianshi Li

. The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.
Toward a Human-Centered Evaluation Framework for
Trustworthy LLM-Powered GUI Agents
Chaoran Chen*, Zhiping Zhang*, Ibrahim Khalilov, Bingcan Guo, Simret A Gebreegziabher, Yanfang Ye, Ziang Xiao, Yaxing Yao, Tianshi Li, Toby Jia-Jun Li


. A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Chaoran Chen, Zhiping Zhang, Bingcan Guo, Shang Ma, Ibrahim Khalilov, Simret A Gebreegziabher, Yanfang Ye, Ziang Xiao, Yaxing Yao, Tianshi Li, Toby Jia-Jun Li


. The advancements of Large Language Models (LLMs) have decentralized the responsibility for the transparency of AI usage. Specifically, LLM users are now encouraged or required to disclose the use of LLM-generated content for varied types of real-world tasks. However, an emerging phenomenon, users’ secret use of LLMs, raises challenges in ensuring end users adhere to the transparency requirement. Our study used mixed-methods with an exploratory survey (125 real-world secret use cases reported) and a controlled experiment among 300 users to investigate the contexts and causes behind the secret use of LLMs. We found that such secretive behavior is often triggered by certain tasks, transcending demographic and personality differences among users. Task types were found to affect users’ intentions to use secretive behavior, primarily through influencing of perceived external judgment regarding LLM usage. Our results yield important insights for future work on designing interventions to encourage more transparent disclosure of LLM/AI use.
Secret Use of Large Language Model (LLM)
Zhiping Zhang, Chenxinran Shen, Bingsheng Yao, Dakuo Wang, and Tianshi Li
In CSCW 2025

“It’s a Fair Game”, or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents
Zhiping Zhang, Michelle Jia, Hao-Ping (Hank) Lee, Bingsheng Yao, Sauvik Das, Ada Lerner, Dakuo Wang, and Tianshi Li
In CHI Conference on Human Factors in Computing Systems Apr 2024
. The widespread use of Large Language Model (LLM)-based conversational agents (CAs), especially in high-stakes domains, raises many privacy concerns. Building ethical LLM-based CAs that respect user privacy requires an in-depth understanding of the privacy risks that concern users the most. However, existing research, primarily model-centered, does not provide insight into users’ perspectives. To bridge this gap, we analyzed sensitive disclosures in real-world ChatGPT conversations and conducted semi-structured interviews with 19 LLM-based CA users. We found that users are constantly faced with trade-offs between privacy, utility, and convenience when using LLM-based CAs. However, users’ erroneous mental models and the dark patterns in system design limited their awareness and comprehension of the privacy risks. Additionally, the human-like interactions encouraged more sensitive disclosures, which complicated users’ ability to navigate the trade-offs. We discuss practical design guidelines and the needs for paradigmatic shifts to protect the privacy of LLM-based CA users.

Human-Centered Privacy Research in the Age of Large Language Models
Tianshi Li, Sauvik Das, Hao-Ping (Hank) Lee, Dakuo Wang, Bingsheng Yao and Zhiping Zhang
In CHI Conference on Human Factors in Computing Systems (CHI’24 Companion) Apr 2024
. The emergence of large language models (LLMs), and their increased use in user-facing systems, has led to substantial privacy concerns. To date, research on these privacy concerns has been model-centered: exploring how LLMs lead to privacy risks like memorization, or can be used to infer personal characteristics about people from their content. We argue that there is a need for more research focusing on the human aspect of these privacy issues: e.g., research on how design paradigms for LLMs affect users' disclosure behaviors, users' mental models and preferences for privacy controls, and the design of tools, systems, and artifacts that empower end-users to reclaim ownership over their personal data. To build usable, efficient, and privacy-friendly systems powered by these models with imperfect privacy properties, our goal is to initiate discussions to outline an agenda for conducting human-centered research on privacy issues in LLM-powered systems. This Special Interest Group (SIG) aims to bring together researchers with backgrounds in usable security and privacy, human-AI collaboration, NLP, or any other related domains to share their perspectives and experiences on this problem, to help our community establish a collective understanding of the challenges, research opportunities, research methods, and strategies to collaborate with researchers outside of HCI.



Robot Role Design for Implementing Social Facilitation Theory in Musical Instruments Practicing
Heqiu Song, Zhiping Zhang, Emilia I. Barakova, Jaap Ham and Panos Markopoulos
In HRI Conference on Human-Robot Interaction 2020
. The application of social robots has recently been explored in various types of educational settings including music learning. Earlier research presented evidence that simply the presence of a robot can influence a person’s task performance, confirming social facilitation theory and findings in human-robot interaction. Confirming the evaluation apprehension theory, earlier studies showed that next to a person’s presence, also that person’s social role could influence a user’s performance: the presence of a (non-) evaluative other can influence the user’s motivation and performance differently. To be able to investigate that, researchers need the roles for the robot which is missing now. In the current research, we describe the design of two social roles (i.e., evaluative role and non-evaluative role) of a robot that can have different appearances. For this, we used the SocibotMini: A robot with a projected face, allowing diversity and great flexibility of human-like social cue presentation. An empirical study at a real practice room including 20 participants confirmed that users (i.e., children) evaluated the robot roles as intended. Thereby, the current research provided the robot roles allowing to study whether the presence of social robots in certain social roles can stimulate practicing behavior and suggestions of how such roles can be designed and improved. Future studies can investigate how the presence of a social robot in a certain social role can stimulate children to practice.
I design and realize.
I believe that good design truly shines when it integrates seamlessly into users' lives, bringing tangible benefits. I bridge theory with practical needs to create applications that matter.
My landed projects that had great impact on our users, achieved commercial success, and earned top international awards. I incorporated the concept of embodied interaction in my designs, enabling technology such as AI to benefit users.

Apply in FITURE 3 PLUS
Embodied Interaction with Light to
Engage In-Home Workout
2022-2023
Worked as the Creative Technologist for the lighting system
(concept, programming and test)
# Embodied Interaction
# Motion Detection
# Light Pattern Coding (Java)
.

Apply in all FITURE intelligent mirrors
Voice Assistant in Multi-Modal Remote Control
.
2021-2023
Worked as the AI Product Manager for the voice assistant.
# Conversational Agent
# Remote Control
# Multi-Modal Interaction
Apply in FEMOOI Skin & Hair Care Device
.
2023
Worked as the HCI Designer for the embodied avatar
(concept and build)
# Human-Agent Interaction
# UX
I make for fun.
Life is short, do sth fun.


.
2023
# Facial Recognition # Head Movement Recognition # Unreal Engine 5

.
2019
# Mimic Player # Machine Learning
# Bayesian Algorithm # Game # Java

.
2018
# Intelligent Facbric # Muscle Detection
# EMG # Wearable # Haptic Feedbacks


.
2019
# Topological Transformation # Temperature & Humidity Sensing # Creative Electronic

.
2018
# Tangible Interaction # Asthma #Health and Wellbeing # Arduino # Processing #Java